
Details of the Target
General Information of Target
| Target ID | LDTP08332 | |||||
|---|---|---|---|---|---|---|
| Target Name | Fibrocystin-L (PKHD1L1) | |||||
| Gene Name | PKHD1L1 | |||||
| Gene ID | 93035 | |||||
| Synonyms |
Fibrocystin-L; Polycystic kidney and hepatic disease 1-like protein 1; PKHD1-like protein 1 |
|||||
| 3D Structure | ||||||
| Sequence |
MGHLWLLGIWGLCGLLLCAADPSTDGSQIIPKVTEIIPKYGSINGATRLTIRGEGFSQAN
QFNYGVDNAELGNSVQLISSFQSITCDVEKDASHSTQITCYTRAMPEDSYTVRVSVDGVP VTENNTCKGHINSWECTFNAKSFRTPTIRSITPLSGTPGTLITIQGRIFTDVYGSNIALS SNGKNVRILRVYIGGMPCELLIPQSDNLYGLKLDHPNGDMGSMVCKTTGTFIGHHNVSFI LDNDYGRSFPQKMAYFVSSLNKIAMFQTYAEVTMIFPSQGSIRGGTTLTISGRFFDQTDF PVRVLVGGEPCDILNVTENSICCKTPPKPHILKTVYPGGRGLKLEVWNNSRPIRLEEILE YNEKTPGYMGASWVDSASYIWLMEQDTFVARFSGFLVAPDSDVYRFYIKGDDRYAIYFSQ TGLPEDKVRIAYHSANANSYFSSPTQRSDDIHLQKGKEYYIEILLQEYRLSAFVDVGLYQ YRNVYTEQQTGDAVNEEQVIKSQSTILQEVQVITLENWETTNAINEVQKIKVTSPCVEAN SCSLYQYRLIYNMEKTVFLPADASEFILQSALNDLWSIKPDTVQVIRTQNPQSYVYMVTF ISTRGDFDLLGYEVVEGNNVTLDITEQTKGKPNLETFTLNWDGIASKPLTLWSSEAEFQG AVEEMVSTKCPPQIANFEEGFVVKYFRDYETDFNLEHINRGQKTAETDAYCGRYSLKNPA VLFDSADVKPNRRPYGDILLFPYNQLCLAYKGFLANYIGLKFQYQDNSKITRSTDTQFTY NFAYGNNWTYTCIDLLDLVRTKYTGTNVSLQRISLHKASESQSFYVDVVYIGHTSTISTL DEMPKRRLPALANKGIFLEHFQVNQTKTNGPTMTNQYSVTMTSYNCSYNIPMMAVSFGQI ITHETENEFVYRGNNWPGESKIHIQRIQAASPPLSGSFDIQAYGHILKGLPAAVSAADLQ FALQSLEGMGRISVTREGTCAGYAWNIKWRSTCGKQNLLQINDSNIIGEKANMTVTRIKE GGLFRQHVLGDLLRTPSQQPQVEVYVNGIPAKCSGDCGFTWDSNITPLVLAISPSQGSYE EGTILTIVGSGFSPSSAVTVSVGPVGCSLLSVDEKELKCQILNGSAGHAPVAVSMADVGL AQNVGGEEFYFVYQSQISHIWPDSGSIAGGTLLTLSGFGFNENSKVLVGNETCNVIEGDL NRITCRTPKKTEGTVDISVTTNGFQATARDAFSYNCLQTPIITDFSPKVRTILGEVNLTI KGYNFGNELTQNMAVYVGGKTCQILHWNFTDIRCLLPKLSPGKHDIYVEVRNWGFASTRD KLNSSIQYVLEVTSMFPQRGSLFGGTEITIRGFGFSTIPAENTVLLGSIPCNVTSSSENV IKCILHSTGNIFRITNNGKDSVHGLGYAWSPPVLNVSVGDTVAWHWQTHPFLRGIGYRIF SVSSPGSVIYDGKGFTSGRQKSTSGSFSYQFTSPGIHYYSSGYVDEAHSIFLQGVINVLP AETRHIPLHLFVGRSEATYAYGGPENLHLGSSVAGCLATEPLCSLNNTRVKNSKRLLFEV SSCFSPSISNITPSTGTVNELITIIGHGFSNLPWANKVTIGSYPCVVEESSEDSITCHID PQNSMDVGIRETVTLTVYNLGTAINTLSNEFDRRFVLLPNIDLVLPNAGSTTGMTSVTIK GSGFAVSSAGVKVLMGHFPCKVLSVNYTAIECETSPAAQQLVDVDLLIHGVPAQCQGNCT FSYLESITPYITGVFPNSVIGSVKVLIEGEGLGTVLEDIAVFIGNQQFRAIEVNENNITA LVTPLPVGHHSVSVVVGSKGLALGNLTVSSPPVASLSPTSGSIGGGTTLVITGNGFYPGN TTVTIGDEPCQIISINPNEVYCRTPAGTTGMVDVKIFVNTIAYPPLLFTYALEDTPFLRG IIPSRGPPGTEIEITGSNFGFEILEISVMINNIQCNVTMANDSVVQCIVGDHAGGTFPVM MHHKTKGSAMSTVVFEYPLNIQNINPSQGSFGGGQTMTVTGTGFNPQNSIILVCGSECAI DRLRSDYTTLLCEIPSNNGTGAEQACEVSVVNGKDLSQSMTPFTYAVSLTPLITAVSPKR GSTAGGTRLTVVGSGFSENMEDVHITIAEAKCDVEYSNKTHIICMTDAHTLSGWAPVCVH IRGVGMAKLDNADFLYVDAWSSNFSWGGKSPPEEGSLVVITKGQTILLDQSTPILKMLLI QGGTLIFDEADIELQAENILITDGGVLQIGTETSPFQHKAVITLHGHLRSPELPVYGAKT LAVREGILDLHGVPVPVTWTRLAHTAKAGERILILQEAVTWKPGDNIVIASTGHRHSQGE NEKMTIASVSADGINITLSNPLNYTHLGITVTLPDGTLFEARAEVGILTRNILIRGSDNV EWNNKIPACPDGFDTGEFATQTCLQGKFGEEIGSDQFGGCVMFHAPVPGANMVTGRIEYV EVFHAGQAFRLGRYPIHWHLLGDLQFKSYVRGCAIHQAYNRAVTIHNTHHLLVERNIIYD IKGGAFFIEDGIEHGNILQYNLAVFVQQSTSLLNDDVTPAAFWVTNPNNTIRHNAVAGGT HFGFWYRMNNHPDGPSYDRNICQKRVPLGEFFNNTVHSQGWFGMWIFEEYFPMQTGSCTS TVPAPAIFNSLTTWNCQKGAEWVNGGALQFHNFVMVNNYEAGIETKRILAPYVGGWGETN GAVIKNAKIVGHLDELGMGSAFCTAKGLVLPFSEGLTVSSVHFMNFDRPNCVALGVTSIS GVCNDRCGGWSAKFVDVQYSHTPNKAGFRWEHEMVMIDVDGSLTGHKGHTVIPHSSLLDP SHCTQEAEWSIGFPGSVCDASVSFHRLAFNQPSPVSLLEKDVVLSDSFGTSIIPFQKKRL THMSGWMALIPNANHINWYFKGVDHITNISYTSTFYGFKEEDYVIISHNFTQNPDMFNII DMRNGSSNPLNWNTSKNGDWHLEANTSTLYYLVSGRNDLHQSQLISGNLDPDVKDVVINF QAYCCILQDCFPVHPPSRKPIPKKRPATYNLWSNDSFWQSSRENNYTVPHPGANVIIPEG TWIVADIDMPSMERLIIWGVLELEDKYNVGAAESSYREVVLNATYISLQGGRLIGGWEDN PFKGDLKIVLRGNHTTQDWALPEGPNQGAKVLGVFGELDLHGIPHSIYKTKLSETAFAGS KVLSLMDAVDWQEGEEIVITTTSYDFHQTETRSIVKILHDHKILILNDSLSYTHFAEKYH VPGTGESYTLAADVGILSRNIKIVGEDYPGWSEDSFGARVLVGSFTENMMTFKGNARISN VEFYHSGQEGFRDSTDPRYAVTFLNLGQIQEHGSSYIRGCAFHHGFSPAIGVFGTDGLDI DDNIIHFTVGEGIRIWGNANRVRGNLIALSVWPGTYQNRKDLSSTLWHAAIEINRGTNTV LQNNVVAGFGRAGYRIDGEPCPGQFNPVEKWFDNEAHGGLYGIYMNQDGLPGCSLIQGFT IWTCWDYGIYFQTTESVHIYNVTLVDNGMAIFPMIYMPAAISHKISSKNVQIKSSLIVGS SPGFNCSDVLTNDDPNIELTAAHRSPRSPSGGRSGICWPTFASAHNMAPRKPHAGIMSYN AISGLLDISGSTFVGFKNVCSGETNVIFITNPLNEDLQHPIHVKNIKLVDTTEQSKIFIH RPDISKVNPSDCVDMVCDAKRKSFLRDIDGSFLGNAGSVIPQAEYEWDGNSQVGIGDYRI PKAMLTFLNGSRIPVTEKAPHKGIIRDSTCKYLPEWQSYQCFGMEYAMMVIESLDPDTET RRLSPVAIMGNGYVDLINGPQDHGWCAGYTCQRRLSLFHSIVALNKSYEVYFTGTSPQNL RLMLLNVDHNKAVLVGIFFSTLQRLDVYVNNLLVCPKTTIWNAQQKHCELNNHLYKDQFL PNLDSTVLGENYFDGTYQMLYLLVKGTIPVEIHTATVIFVSFQLSVATEDDFYTSHNLVK NLALFLKIPSDKIRISKIRGKSLRRKRSMGFIIEIEIGDPPIQFISNGTTGQMQLSELQE IAGSLGQAVILGNISSILGFNISSMSITNPLPSPSDSGWIKVTAQPVERSAFPVHHVAFV SSLLVITQPVAAQPGQPFPQQPSVKATDSDGNCVSVGITALTLRAILKDSNNNQVNGLSG NTTIPFSSCWANYTDLTPLRTGKNYKIEFILDNVVGVESRTFSLLAESVSSSGSSSSSNS KASTVGTYAQIMTVVISCLVGRMWLLEIFMAAVSTLNITLRSY |
|||||
| Target Bioclass |
Other
|
|||||
| Subcellular location |
Membrane
|
|||||
| Uniprot ID | ||||||
| Ensemble ID | ||||||
| HGNC ID | ||||||
Probe(s) Labeling This Target
ABPP Probe
| Probe name | Structure | Binding Site(Ratio) | Interaction ID | Ref | |
|---|---|---|---|---|---|
|
W1 Probe Info |
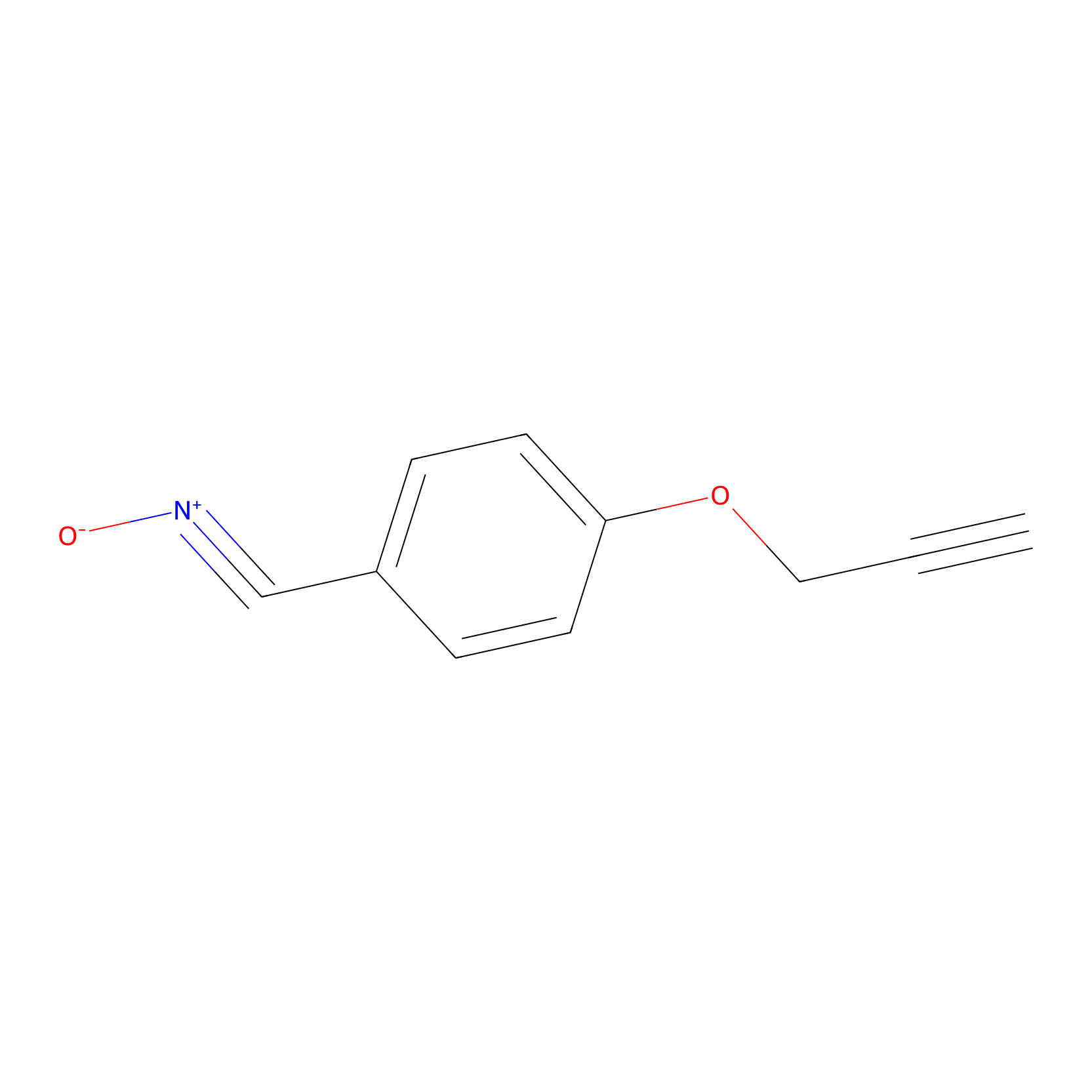 |
R4069(0.58); Q4065(0.58) | LDD0239 | [1] | |
|
IA-alkyne Probe Info |
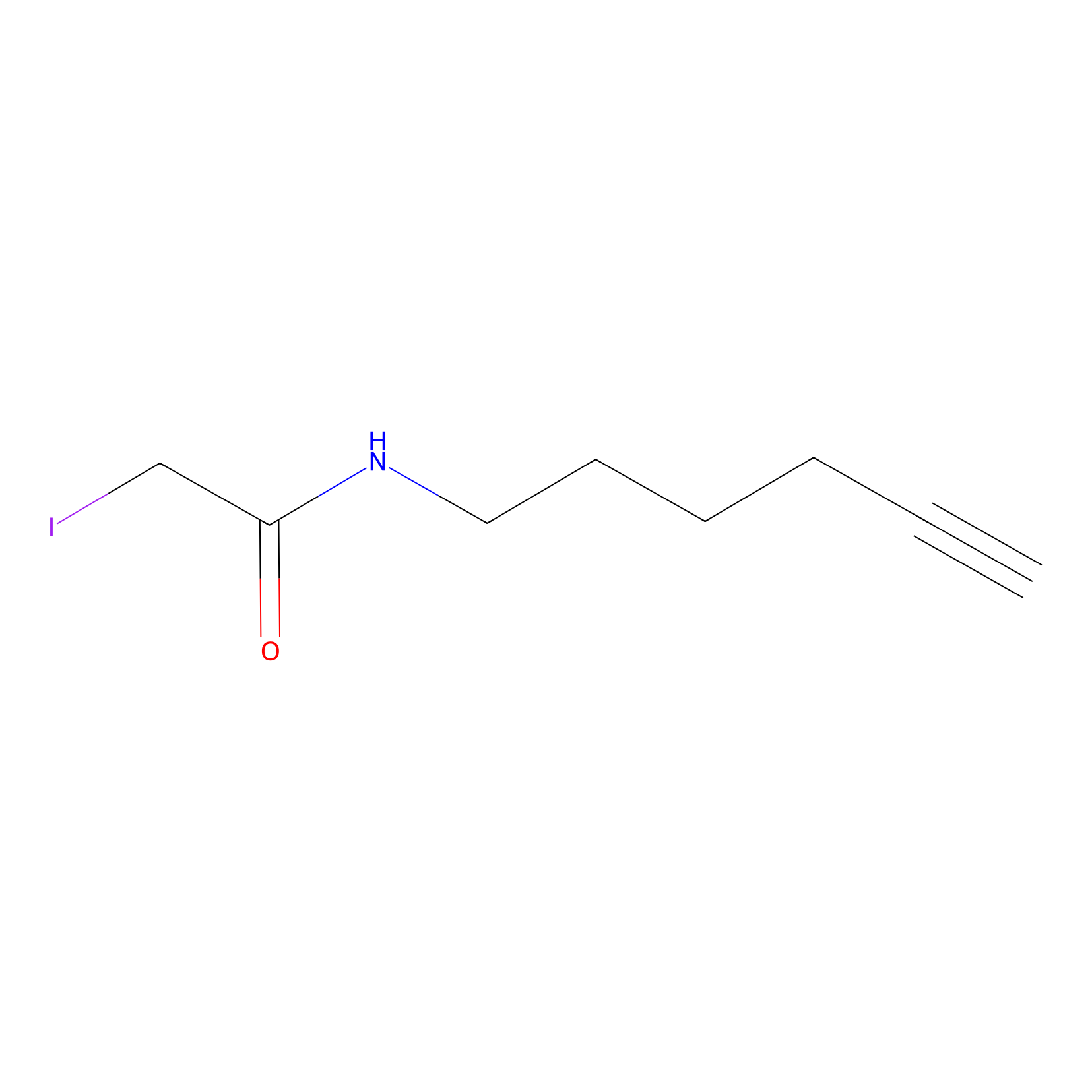 |
N.A. | LDD0165 | [2] | |
Competitor(s) Related to This Target
References