
Details of the Target
General Information of Target
| Target ID | LDTP07209 | |||||
|---|---|---|---|---|---|---|
| Target Name | Obscurin (OBSCN) | |||||
| Gene Name | OBSCN | |||||
| Gene ID | 84033 | |||||
| Synonyms |
KIAA1556; KIAA1639; Obscurin; EC 2.7.11.1; Obscurin-RhoGEF; Obscurin-myosin light chain kinase; Obscurin-MLCK |
|||||
| 3D Structure | ||||||
| Sequence |
MDQPQFSGAPRFLTRPKAFVVSVGKDATLSCQIVGNPTPQVSWEKDQQPVAAGARFRLAQ
DGDLYRLTILDLALGDSGQYVCRARNAIGEAFAAVGLQVDAEAACAEQAPHFLLRPTSIR VREGSEATFRCRVGGSPRPAVSWSKDGRRLGEPDGPRVRVEELGEASALRIRAARPRDGG TYEVRAENPLGAASAAAALVVDSDAADTASRPGTSTAALLAHLQRRREAMRAEGAPASPP STGTRTCTVTEGKHARLSCYVTGEPKPETVWKKDGQLVTEGRRHVVYEDAQENFVLKILF CKQSDRGLYTCTASNLVGQTYSSVLVVVREPAVPFKKRLQDLEVREKESATFLCEVPQPS TEAAWFKEETRLWASAKYGIEEEGTERRLTVRNVSADDDAVYICETPEGSRTVAELAVQG NLLRKLPRKTAVRVGDTAMFCVELAVPVGPVHWLRNQEEVVAGGRVAISAEGTRHTLTIS QCCLEDVGQVAFMAGDCQTSTQFCVSAPRKPPLQPPVDPVVKARMESSVILSWSPPPHGE RPVTIDGYLVEKKKLGTYTWIRCHEAEWVATPELTVADVAEEGNFQFRVSALNSFGQSPY LEFPGTVHLAPKLAVRTPLKAVQAVEGGEVTFSVDLTVASAGEWFLDGQALKASSVYEIH CDRTRHTLTIREVPASLHGAQLKFVANGIESSIRMEVRAAPGLTANKPPAAAAREVLARL HEEAQLLAELSDQAAAVTWLKDGRTLSPGPKYEVQASAGRRVLLVRDVARDDAGLYECVS RGGRIAYQLSVQGLARFLHKDMAGSCVDAVAGGPAQFECETSEAHVHVHWYKDGMELGHS GERFLQEDVGTRHRLVAATVTRQDEGTYSCRVGEDSVDFRLRVSEPKVVFAKEQLARRKL QAEAGASATLSCEVAQAQTEVTWYKDGKKLSSSSKVCMEATGCTRRLVVQQAGQADAGEY SCEAGGQRLSFHLDVKEPKVVFAKDQVAHSEVQAEAGASATLSCEVAQAQTEVMWYKDGK KLSSSLKVHVEAKGCRRRLVVQQAGKTDAGDYSCEARGQRVSFRLHITEPKMMFAKEQSV HNEVQAEAGASAMLSCEVAQAQTEVTWYKDGKKLSSSSKVGMEVKGCTRRLVLPQAGKAD AGEYSCEAGGQRVSFHLHITEPKGVFAKEQSVHNEVQAEAGTTAMLSCEVAQPQTEVTWY KDGKKLSSSSKVRMEVKGCTRRLVVQQVGKADAGEYSCEAGGQRVSFQLHITEPKAVFAK EQLVHNEVRTEAGASATLSCEVAQAQTEVTWYKDGKKLSSSSKVRIEAAGCMRQLVVQQA GQADAGEYTCEAGGQRLSFHLDVSEPKAVFAKEQLAHRKVQAEAGAIATLSCEVAQAQTE VTWYKDGKKLSSSSKVRMEAVGCTRRLVVQQACQADTGEYSCEAGGQRLSFSLDVAEPKV VFAKEQPVHREVQAQAGASTTLSCEVAQAQTEVMWYKDGKKLSFSSKVRMEAVGCTRRLV VQQAGQAVAGEYSCEAGSQRLSFHLHVAEPKAVFAKEQPASREVQAEAGTSATLSCEVAQ AQTEVTWYKDGKKLSSSSKVRMEAVGCTRRLVVQEAGQADAGEYSCKAGDQRLSFHLHVA EPKVVFAKEQPAHREVQAEAGASATLSCEVAQAQTEVTWYKDGKKLSSSSKVRVEAVGCT RRLVVQQAGQAEAGEYSCEAGGQQLSFRLQVAELEPQISERPCRREPLVVKEHEDIILTA TLATPSAATVTWLKDGVEIRRSKRHETASQGDTHTLTVHGAQVLDSAIYSCRVGAEGQDF PVQVEEVAAKFCRLLEPVCGELGGTVTLACELSPACAEVVWRCGNTQLRVGKRFQMVAEG PVRSLTVLGLRAEDAGEYVCESRDDHTSAQLTVSVPRVVKFMSGLSTVVAEEGGEATFQC VVSPSDVAVVWFRDGALLQPSEKFAISQSGASHSLTISDLVLEDAGQITVEAEGASSSAA LRVREAPVLFKKKLEPQTVEERSSVTLEVELTRPWPELRWTRNATALAPGKNVEIHAEGA RHRLVLHNVGFADRGFFGCETPDDKTQAKLTVEMRQVRLVRGLQAVEAREQGTATMEVQL SHADVDGSWTRDGLRFQQGPTCHLAVRGPMHTLTLSGLRPEDSGLMVFKAEGVHTSARLV VTELPVSFSRPLQDVVTTEKEKVTLECELSRPNVDVRWLKDGVELRAGKTMAIAAQGACR SLTIYRCEFADQGVYVCDAHDAQSSASVKVQGRTYTLIYRRVLAEDAGEIQFVAENAESR AQLRVKELPVTLVRPLRDKIAMEKHRGVLECQVSRASAQVRWFKGSQELQPGPKYELVSD GLYRKLIISDVHAEDEDTYTCDAGDVKTSAQFFVEEQSITIVRGLQDVTVMEPAPAWFEC ETSIPSVRPPKWLLGKTVLQAGGNVGLEQEGTVHRLMLRRTCSTMTGPVHFTVGKSRSSA RLVVSDIPVVLTRPLEPKTGRELQSVVLSCDFRPAPKAVQWYKDDTPLSPSEKFKMSLEG QMAELRILRLMPADAGVYRCQAGSAHSSTEVTVEAREVTVTGPLQDAEATEEGWASFSCE LSHEDEEVEWSLNGMPLYNDSFHEISHKGRRHTLVLKSIQRADAGIVRASSLKVSTSARL EVRVKPVVFLKALDDLSAEERGTLALQCEVSDPEAHVVWRKDGVQLGPSDKYDFLHTAGT RGLVVHDVSPEDAGLYTCHVGSEETRARVRVHDLHVGITKRLKTMEVLEGESCSFECVLS HESASDPAMWTVGGKTVGSSSRFQATRQGRKYILVVREAAPSDAGEVVFSVRGLTSKASL IVRERPAAIIKPLEDQWVAPGEDVELRCELSRAGTPVHWLKDRKAIRKSQKYDVVCEGTM AMLVIRGASLKDAGEYTCEVEASKSTASLHVEEKANCFTEELTNLQVEEKGTAVFTCKTE HPAATVTWRKGLLELRASGKHQPSQEGLTLRLTISALEKADSDTYTCDIGQAQSRAQLLV QGRRVHIIEDLEDVDVQEGSSATFRCRISPANYEPVHWFLDKTPLHANELNEIDAQPGGY HVLTLRQLALKDSGTIYFEAGDQRASAALRVTEKPSVFSRELTDATITEGEDLTLVCETS TCDIPVCWTKDGKTLRGSARCQLSHEGHRAQLLITGATLQDSGRYKCEAGGACSSSIVRV HARPVRFQEALKDLEVLEGGAATLRCVLSSVAAPVKWCYGNNVLRPGDKYSLRQEGAMLE LVVRNLRPQDSGRYSCSFGDQTTSATLTVTALPAQFIGKLRNKEATEGATATLRCELSKA APVEWRKGSETLRDGDRYCLRQDGAMCELQIRGLAMVDAAEYSCVCGEERTSASLTIRPM PAHFIGRLRHQESIEGATATLRCELSKAAPVEWRKGRESLRDGDRHSLRQDGAVCELQIC GLAVADAGEYSCVCGEERTSATLTVKALPAKFTEGLRNEEAVEGATAMLWCELSKVAPVE WRKGPENLRDGDRYILRQEGTRCELQICGLAMADAGEYLCVCGQERTSATLTIRALPARF IEDVKNQEAREGATAVLQCELNSAAPVEWRKGSETLRDGDRYSLRQDGTKCELQIRGLAM ADTGEYSCVCGQERTSAMLTVRALPIKFTEGLRNEEATEGATAVLRCELSKMAPVEWWKG HETLRDGDRHSLRQDGARCELQIRGLVAEDAGEYLCMCGKERTSAMLTVRAMPSKFIEGL RNEEATEGDTATLWCELSKAAPVEWRKGHETLRDGDRHSLRQDGSRCELQIRGLAVVDAG EYSCVCGQERTSATLTVRALPARFIEDVKNQEAREGATAVLQCELSKAAPVEWRKGSETL RGGDRYSLRQDGTRCELQIHGLSVADTGEYSCVCGQERTSATLTVRAPQPVFREPLQSLQ AEEGSTATLQCELSEPTATVVWSKGGLQLQANGRREPRLQGCTAELVLQDLQREDTGEYT CTCGSQATSATLTVTAAPVRFLRELQHQEVDEGGTAHLCCELSRAGASVEWRKGSLQLFP CAKYQMVQDGAAAELLVRGVEQEDAGDYTCDTGHTQSMASLSVRVPRPKFKTRLQSLEQE TGDIARLCCQLSDAESGAVVQWLKEGVELHAGPKYEMRSQGATRELLIHQLEAKDTGEYA CVTGGQKTAASLRVTEPEVTIVRGLVDAEVTADEDVEFSCEVSRAGATGVQWCLQGLPLQ SNEVTEVAVRDGRIHTLRLKGVTPEDAGTVSFHLGNHASSAQLTVRAPEVTILEPLQDVQ LSEGQDASFQCRLSRASGQEARWALGGVPLQANEMNDITVEQGTLHLLTLHKVTLEDAGT VSFHVGTCSSEAQLKVTAKNTVVRGLENVEALEGGEALFECQLSQPEVAAHTWLLDDEPV HTSENAEVVFFENGLRHLLLLKNLRPQDSCRVTFLAGDMVTSAFLTVRGWRLEILEPLKN AAVRAGAQACFTCTLSEAVPVGEASWYINGAAVQPDDSDWTVTADGSHHALLLRSAQPHH AGEVTFACRDAVASARLTVLGLPDPPEDAEVVARSSHTVTLSWAAPMSDGGGGLCGYRVE VKEGATGQWRLCHELVPGPECVVDGLAPGETYRFRVAAVGPVGAGEPVHLPQTVRLAEPP KPVPPQPSAPESRQVAAGEDVSLELEVVAEAGEVIWHKGMERIQPGGRFEVVSQGRQQML VIKGFTAEDQGEYHCGLAQGSICPAAATFQVALSPASVDEAPQPSLPPEAAQEGDLHLLW EALARKRRMSREPTLDSISELPEEDGRSQRLPQEAEEVAPDLSEGYSTADELARTGDADL SHTSSDDESRAGTPSLVTYLKKAGRPGTSPLASKVGAPAAPSVKPQQQQEPLAAVRPPLG DLSTKDLGDPSMDKAAVKIQAAFKGYKVRKEMKQQEGPMFSHTFGDTEAQVGDALRLECV VASKADVRARWLKDGVELTDGRHHHIDQLGDGTCSLLITGLDRADAGCYTCQVSNKFGQV THSACVVVSGSESEAESSSGGELDDAFRRAARRLHRLFRTKSPAEVSDEELFLSADEGPA EPEEPADWQTYREDEHFICIRFEALTEARQAVTRFQEMFATLGIGVEIKLVEQGPRRVEM CISKETPAPVVPPEPLPSLLTSDAAPVFLTELQNQEVQDGYPVSFDCVVTGQPMPSVRWF KDGKLLEEDDHYMINEDQQGGHQLIITAVVPADMGVYRCLAENSMGVSSTKAELRVDLTS TDYDTAADATESSSYFSAQGYLSSREQEGTESTTDEGQLPQVVEELRDLQVAPGTRLAKF QLKVKGYPAPRLYWFKDGQPLTASAHIRMTDKKILHTLEIISVTREDSGQYAAYISNAMG AAYSSARLLVRGPDEPEEKPASDVHEQLVPPRMLERFTPKKVKKGSSITFSVKVEGRPVP TVHWLREEAERGVLWIGPDTPGYTVASSAQQHSLVLLDVGRQHQGTYTCIASNAAGQALC SASLHVSGLPKVEEQEKVKEALISTFLQGTTQAISAQGLETASFADLGGQRKEEPLAAKE ALGHLSLAEVGTEEFLQKLTSQITEMVSAKITQAKLQVPGGDSDEDSKTPSASPRHGRSR PSSSIQESSSESEDGDARGEIFDIYVVTADYLPLGAEQDAITLREGQYVEVLDAAHPLRW LVRTKPTKSSPSRQGWVSPAYLDRRLKLSPEWGAAEAPEFPGEAVSEDEYKARLSSVIQE LLSSEQAFVEELQFLQSHHLQHLERCPHVPIAVAGQKAVIFRNVRDIGRFHSSFLQELQQ CDTDDDVAMCFIKNQAAFEQYLEFLVGRVQAESVVVSTAIQEFYKKYAEEALLAGDPSQP PPPPLQHYLEQPVERVQRYQALLKELIRNKARNRQNCALLEQAYAVVSALPQRAENKLHV SLMENYPGTLQALGEPIRQGHFIVWEGAPGARMPWKGHNRHVFLFRNHLVICKPRRDSRT DTVSYVFRNMMKLSSIDLNDQVEGDDRAFEVWQEREDSVRKYLLQARTAIIKSSWVKEIC GIQQRLALPVWRPPDFEEELADCTAELGETVKLACRVTGTPKPVISWYKDGKAVQVDPHH ILIEDPDGSCALILDSLTGVDSGQYMCFAASAAGNCSTLGKILVQVPPRFVNKVRASPFV EGEDAQFTCTIEGAPYPQIRWYKDGALLTTGNKFQTLSEPRSGLLVLVIRAASKEDLGLY ECELVNRLGSARASAELRIQSPMLQAQEQCHREQLVAAVEDTTLERADQEVTSVLKRLLG PKAPGPSTGDLTGPGPCPRGAPALQETGSQPPVTGTSEAPAVPPRVPQPLLHEGPEQEPE AIARAQEWTVPIRMEGAAWPGAGTGELLWDVHSHVVRETTQRTYTYQAIDTHTARPPSMQ VTIEDVQAQTGGTAQFEAIIEGDPQPSVTWYKDSVQLVDSTRLSQQQEGTTYSLVLRHVA SKDAGVYTCLAQNTGGQVLCKAELLVLGGDNEPDSEKQSHRRKLHSFYEVKEEIGRGVFG FVKRVQHKGNKILCAAKFIPLRSRTRAQAYRERDILAALSHPLVTGLLDQFETRKTLILI LELCSSEELLDRLYRKGVVTEAEVKVYIQQLVEGLHYLHSHGVLHLDIKPSNILMVHPAR EDIKICDFGFAQNITPAELQFSQYGSPEFVSPEIIQQNPVSEASDIWAMGVISYLSLTCS SPFAGESDRATLLNVLEGRVSWSSPMAAHLSEDAKDFIKATLQRAPQARPSAAQCLSHPW FLKSMPAEEAHFINTKQLKFLLARSRWQRSLMSYKSILVMRSIPELLRGPPDSPSLGVAR HLCRDTGGSSSSSSSSDNELAPFARAKSLPPSPVTHSPLLHPRGFLRPSASLPEEAEASE RSTEAPAPPASPEGAGPPAAQGCVPRHSVIRSLFYHQAGESPEHGALAPGSRRHPARRRH LLKGGYIAGALPGLREPLMEHRVLEEEAAREEQATLLAKAPSFETALRLPASGTHLAPGH SHSLEHDSPSTPRPSSEACGEAQRLPSAPSGGAPIRDMGHPQGSKQLPSTGGHPGTAQPE RPSPDSPWGQPAPFCHPKQGSAPQEGCSPHPAVAPCPPGSFPPGSCKEAPLVPSSPFLGQ PQAPPAPAKASPPLDSKMGPGDISLPGRPKPGPCSSPGSASQASSSQVSSLRVGSSQVGT EPGPSLDAEGWTQEAEDLSDSTPTLQRPQEQATMRKFSLGGRGGYAGVAGYGTFAFGGDA GGMLGQGPMWARIAWAVSQSEEEEQEEARAESQSEEQQEARAESPLPQVSARPVPEVGRA PTRSSPEPTPWEDIGQVSLVQIRDLSGDAEAADTISLDISEVDPAYLNLSDLYDIKYLPF EFMIFRKVPKSAQPEPPSPMAEEELAEFPEPTWPWPGELGPHAGLEITEESEDVDALLAE AAVGRKRKWSSPSRSLFHFPGRHLPLDEPAELGLRERVKASVEHISRILKGRPEGLEKEG PPRKKPGLASFRLSGLKSWDRAPTFLRELSDETVVLGQSVTLACQVSAQPAAQATWSKDG APLESSSRVLISATLKNFQLLTILVVVAEDLGVYTCSVSNALGTVTTTGVLRKAERPSSS PCPDIGEVYADGVLLVWKPVESYGPVTYIVQCSLEGGSWTTLASDIFDCCYLTSKLSRGG TYTFRTACVSKAGMGPYSSPSEQVLLGGPSHLASEEESQGRSAQPLPSTKTFAFQTQIQR GRFSVVRQCWEKASGRALAAKIIPYHPKDKTAVLREYEALKGLRHPHLAQLHAAYLSPRH LVLILELCSGPELLPCLAERASYSESEVKDYLWQMLSATQYLHNQHILHLDLRSENMIIT EYNLLKVVDLGNAQSLSQEKVLPSDKFKDYLETMAPELLEGQGAVPQTDIWAIGVTAFIM LSAEYPVSSEGARDLQRGLRKGLVRLSRCYAGLSGGAVAFLRSTLCAQPWGRPCASSCLQ CPWLTEEGPACSRPAPVTFPTARLRVFVRNREKRRALLYKRHNLAQVR |
|||||
| Target Bioclass |
Enzyme
|
|||||
| Family |
Protein kinase superfamily, CAMK Ser/Thr protein kinase family
|
|||||
| Subcellular location |
Cytoplasm, myofibril, sarcomere, M line
|
|||||
| Function |
Structural component of striated muscles which plays a role in myofibrillogenesis. Probably involved in the assembly of myosin into sarcomeric A bands in striated muscle. Has serine/threonine protein kinase activity and phosphorylates N-cadherin CDH2 and sodium/potassium-transporting ATPase subunit ATP1B1. Binds (via the PH domain) strongly to phosphatidylinositol 3,4-bisphosphate (PtdIns(3,4)P2) and phosphatidylinositol 4,5-bisphosphate (PtdIns(4,5)P2), and to a lesser extent to phosphatidylinositol 3-phosphate (PtdIns(3)P), phosphatidylinositol 4-phosphate (PtdIns(4)P), phosphatidylinositol 5-phosphate (PtdIns(5)P) and phosphatidylinositol 3,4,5-trisphosphate (PtdIns(3,4,5)P3).
|
|||||
| Uniprot ID | ||||||
| Ensemble ID | ||||||
| HGNC ID | ||||||
Probe(s) Labeling This Target
ABPP Probe
| Probe name | Structure | Binding Site(Ratio) | Interaction ID | Ref | |
|---|---|---|---|---|---|
|
CY4 Probe Info |
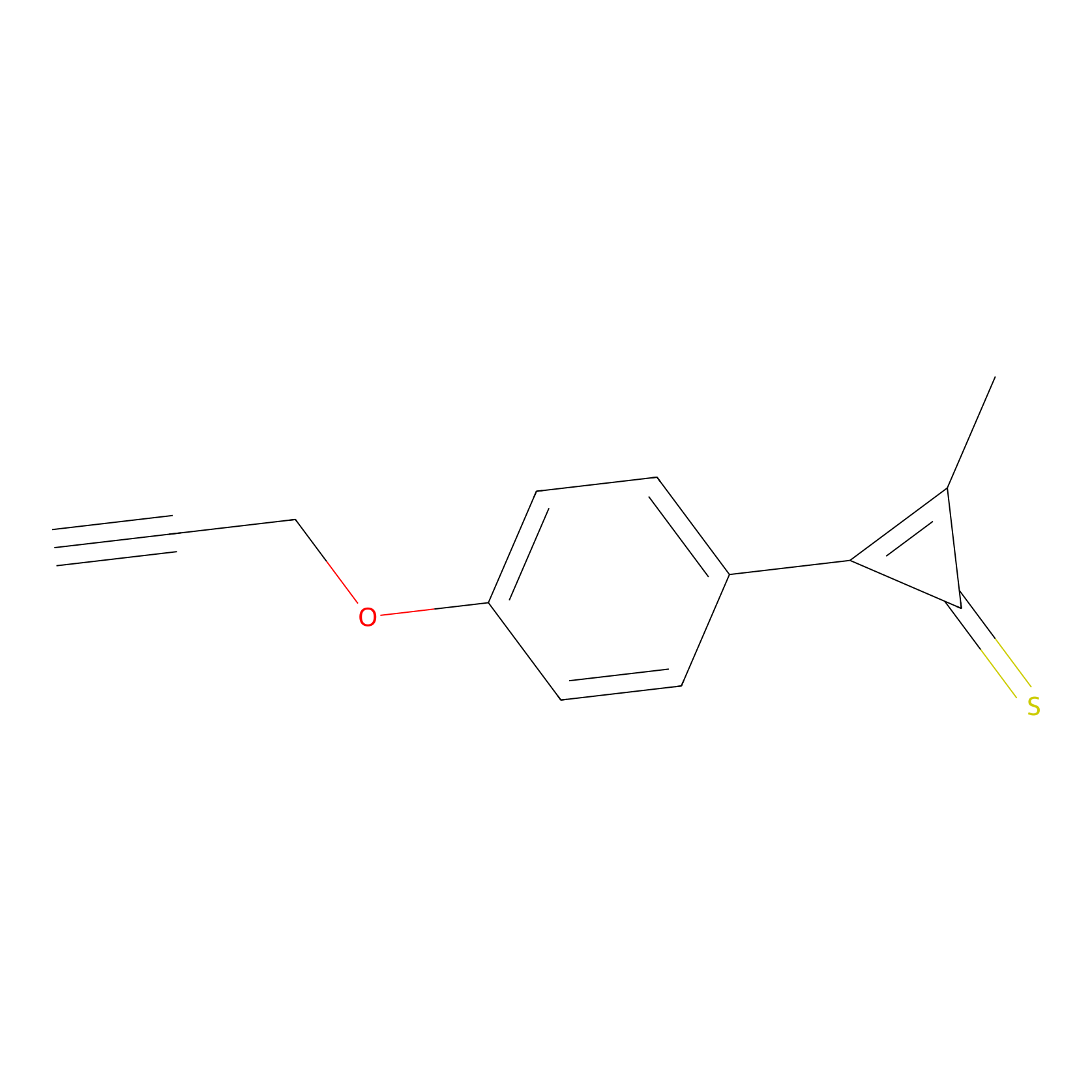 |
C3327(0.00); E3328(0.00); Q3330(0.00); R3332(0.00) | LDD0247 | [1] | |
|
IA-alkyne Probe Info |
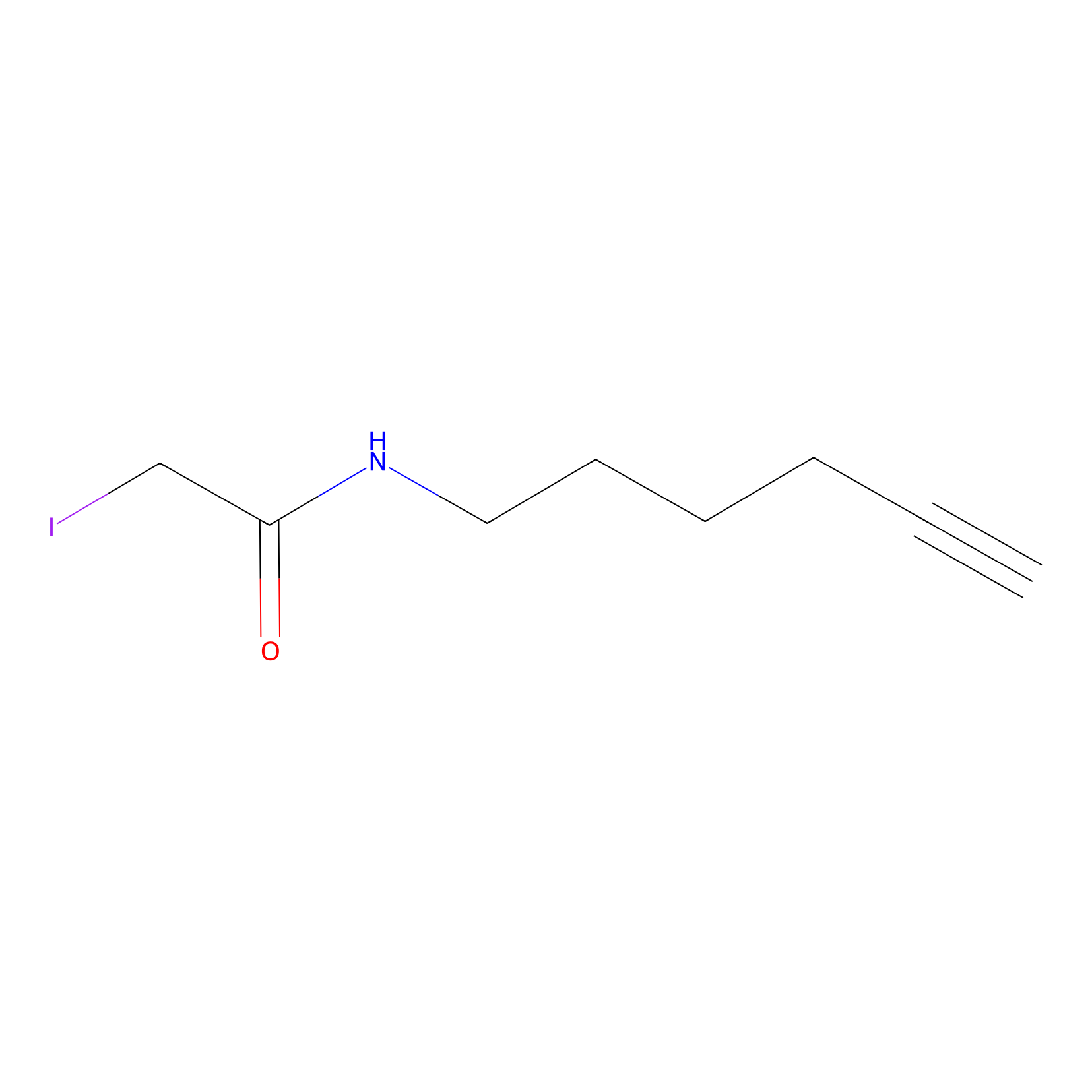 |
N.A. | LDD0167 | [2] | |
|
TFBX Probe Info |
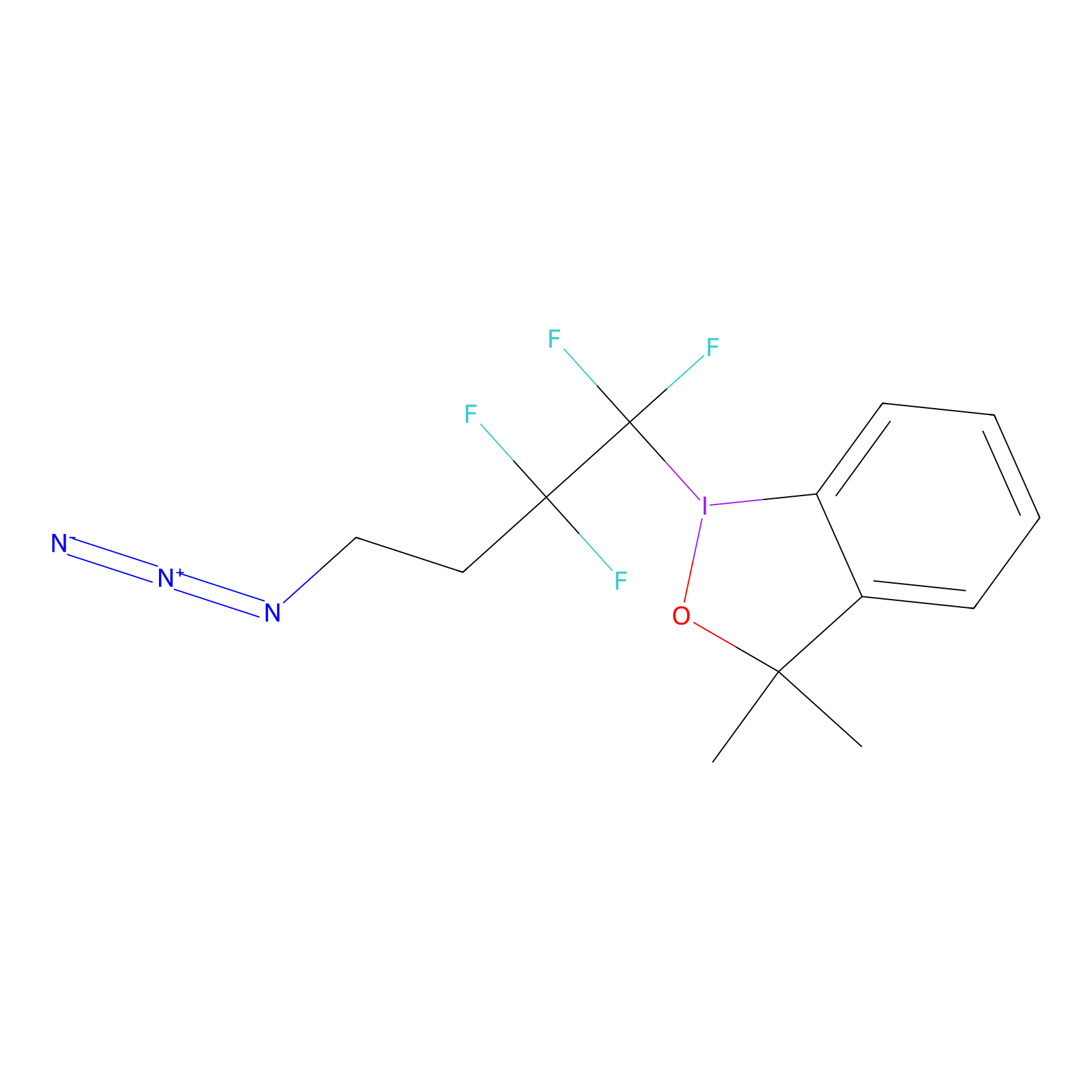 |
N.A. | LDD0148 | [3] | |
The Interaction Atlas With This Target
References