
Details of the Target
General Information of Target
| Target ID | LDTP12223 | |||||
|---|---|---|---|---|---|---|
| Target Name | Calpain-10 (CAPN10) | |||||
| Gene Name | CAPN10 | |||||
| Gene ID | 11132 | |||||
| Synonyms |
KIAA1845; Calpain-10; EC 3.4.22.-; Calcium-activated neutral proteinase 10; CANP 10 |
|||||
| 3D Structure | ||||||
| Sequence |
MGAPSACRTLVLALAAMLVVPQAETQGPVEPSWENAGHTMDGGAPTSSPTRRVSFVPPVT
VFPSLSPLNPAHNGRVCSTWGDFHYKTFDGDVFRFPGLCNYVFSEHCRAAYEDFNVQLRR GLVGSRPVVTRVVIKAQGLVLEASNGSVLINGQREELPYSRTGLLVEQSGDYIKVSIRLV LTFLWNGEDSALLELDPKYANQTCGLCGDFNGLPAFNEFYAHNARLTPLQFGNLQKLDGP TEQCPDPLPLPAGNCTDEEGICHRTLLGPAFAECHALVDSTAYLAACAQDLCRCPTCPCA TFVEYSRQCAHAGGQPRNWRCPELCPRTCPLNMQHQECGSPCTDTCSNPQRAQLCEDHCV DGCFCPPGTVLDDITHSGCLPLGQCPCTHGGRTYSPGTSFNTTCSSCTCSGGLWQCQDLP CPGTCSVQGGAHISTYDEKLYDLHGDCSYVLSKKCADSSFTVLAELRKCGLTDNENCLKA VTLSLDGGDTAIRVQADGGVFLNSIYTQLPLSAANITLFTPSSFFIVVQTGLGLQLLVQL VPLMQVFVRLDPAHQGQMCGLCGNFNQNQADDFTALSGVVEATGAAFANTWKAQAACANA RNSFEDPCSLSVENENYARHWCSRLTDPNSAFSRCHSIINPKPFHSNCMFDTCNCERSED CLCAALSSYVHACAAKGVQLSDWRDGVCTKYMQNCPKSQRYAYVVDACQPTCRGLSEADV TCSVSFVPVDGCTCPAGTFLNDAGACVPAQECPCYAHGTVLAPGEVVHDEGAVCSCTGGK LSCLGASLQKSTGCAAPMVYLDCSNSSAGTPGAECLRSCHTLDVGCFSTHCVSGCVCPPG LVSDGSGGCIAEEDCPCVHNEATYKPGETIRVDCNTCTCRNRRWECSHRLCLGTCVAYGD GHFITFDGDRYSFEGSCEYILAQDYCGDNTTHGTFRIVTENIPCGTTGTTCSKAIKLFVE SYELILQEGTFKAVARGPGGDPPYKIRYMGIFLVIETHGMAVSWDRKTSVFIRLHQDYKG RVCGLCGNFDDNAINDFATRSRSVVGDALEFGNSWKLSPSCPDALAPKDPCTANPFRKSW AQKQCSILHGPTFAACRSQVDSTKYYEACVNDACACDSGGDCECFCTAVAAYAQACHDAG LCVSWRTPDTCPLFCDFYNPHGGCEWHYQPCGAPCLKTCRNPSGHCLVDLPGLEGCYPKC PPSQPFFNEDQMKCVAQCGCYDKDGNYYDVGARVPTAENCQSCNCTPSGIQCAHSLEACT CTYEDRTYSYQDVIYNTTDGLGACLIAICGSNGTIIRKAVACPGTPATTPFTFTTAWVPH STTSPALPVSTVCVREVCRWSSWYNGHRPEPGLGGGDFETFENLRQRGYQVCPVLADIEC RAAQLPDMPLEELGQQVDCDRMRGLMCANSQQSPPLCHDYELRVLCCEYVPCGPSPAPGT SPQPSLSASTEPAVPTPTQTTATEKTTLWVTPSIRSTAALTSQTGSSSGPVTVTPSAPGT TTCQPRCQWTEWFDEDYPKSEQLGGDVESYDKIRAAGGHLCQQPKDIECQAESFPNWTLA QVGQKVHCDVHFGLVCRNWEQEGVFKMCYNYRIRVLCCSDDHCRGRATTPPPTTELETAT TTTTQALFSTPQPTSSPGLTRAPPASTTAVPTLSEGLTSPRYTSTLGTATTGGPTTPAGS TEPTVPGVATSTLPTRSALPGTTGSLGTWRPSQPPTLAPTTMATSRARPTGTASTASKEP LTTSLAPTLTSELSTSQAETSTPRTETTMSPLTNTTTSQGTTRCQPKCEWTEWFDVDFPT SGVAGGDMETFENIRAAGGKMCWAPKSIECRAENYPEVSIDQVGQVLTCSLETGLTCKNE DQTGRFNMCFNYNVRVLCCDDYSHCPSTPATSSTATPSSTPGTTWILTKPTTTATTTAST GSTATPTSTLRTAPPPKVLTTTATTPTVTSSKATPSSSPGTATALPALRSTATTPTATSV TPIPSSSLGTTWTRLSQTTTPTATMSTATPSSTPETAHTSTVLTATATTTGATGSVATPS STPGTAHTTKVPTTTTTGFTATPSSSPGTALTPPVWISTTTTPTTRGSTVTPSSIPGTTH TATVLTTTTTTVATGSMATPSSSTQTSGTPPSLTTTATTITATGSTTNPSSTPGTTPIPP VLTTTATTPAATSNTVTPSSALGTTHTPPVPNTMATTHGRSLPPSSPHTVRTAWTSATSG ILGTTHITEPSTVTSHTLAATTGTTQHSTPALSSPHPSSRTTESPPSPGTTTPGHTTATS RTTATATPSKTRTSTLLPSSPTSAPITTVVTMGCEPQCAWSEWLDYSYPMPGPSGGDFDT YSNIRAAGGAVCEQPLGLECRAQAQPGVPLRELGQVVECSLDFGLVCRNREQVGKFKMCF NYEIRVFCCNYGHCPSTPATSSTAMPSSTPGTTWILTELTTTATTTESTGSTATPSSTPG TTWILTEPSTTATVTVPTGSTATASSTQATAGTPHVSTTATTPTVTSSKATPFSSPGTAT ALPALRSTATTPTATSFTAIPSSSLGTTWTRLSQTTTPTATMSTATPSSTPETVHTSTVL TTTATTTGATGSVATPSSTPGTAHTTKVLTTTTTGFTATPSSSPGTARTLPVWISTTTTP TTRGSTVTPSSIPGTTHTPTVLTTTTTTVATGSMATPSSSTQTSGTPPSLTTTATTITAT GSTTNPSSTPGTTPIPPVLTTTATTPAATSSTVTPSSALGTTHTPPVPNTTATTHGRSLS PSSPHTVRTAWTSATSGTLGTTHITEPSTGTSHTPAATTGTTQHSTPALSSPHPSSRTTE SPPSPGTTTPGHTRATSRTTATATPSKTRTSTLLPSSPTSAPITTVVTMGCEPQCAWSEW LDYSYPMPGPSGGDFDTYSNIRAAGGAVCEQPLGLECRAQAQPGVPLRELGQVVECSLDF GLVCRNREQVGKFKMCFNYEIRVFCCNYGHCPSTPATSSTATPSSTPGTTWILTEQTTAA TTTATTGSTAIPSSTPGTAPPPKVLTSTATTPTATSSKATSSSSPRTATTLPVLTSTATK STATSFTPIPSFTLGTTGTLPEQTTTPMATMSTIHPSSTPETTHTSTVLTTKATTTRATS SMSTPSSTPGTTWILTELTTAATTTAATGPTATPSSTPGTTWILTEPSTTATVTVPTGST ATASSTRATAGTLKVLTSTATTPTVISSRATPSSSPGTATALPALRSTATTPTATSVTAI PSSSLGTAWTRLSQTTTPTATMSTATPSSTPETVHTSTVLTTTTTTTRATGSVATPSSTP GTAHTTKVPTTTTTGFTATPSSSPGTALTPPVWISTTTTPTTRGSTVTPSSIPGTTHTAT VLTTTTTTVATGSMATPSSSTQTSGTPPSLTTTATTITATGSTTNPSSTPGTTPIPPVLT TTATTPAATSSTVTPSSALGTTHTPPVPNTTATTHGRSLPPSSPHTVRTAWTSATSGILG TTHITEPSTVTSHTPAATTSTTQHSTPALSSPHPSSRTTESPPSPGTTTPGHTRGTSRTT ATATPSKTRTSTLLPSSPTSAPITTVVTTGCEPQCAWSEWLDYSYPMPGPSGGDFDTYSN IRAAGGAVCEQPLGLECRAQAQPGVPLRELGQVVECSLDFGLVCRNREQVGKFKMCFNYE IRVFCCNYGHCPSTPATSSTATPSSTPGTTWILTKLTTTATTTESTGSTATPSSTPGTTW ILTEPSTTATVTVPTGSTATASSTQATAGTPHVSTTATTPTVTSSKATPFSSPGTATALP ALRSTATTPTATSFTAIPSSSLGTTWTRLSQTTTPTATMSTATPSSTPETAHTSTVLTTT ATTTRATGSVATPSSTPGTAHTTKVPTTTTTGFTVTPSSSPGTARTPPVWISTTTTPTTS GSTVTPSSVPGTTHTPTVLTTTTTTVATGSMATPSSSTQTSGTPPSLITTATTITATGST TNPSSTPGTTPIPPVLTTTATTPAATSSTVTPSSALGTTHTPPVPNTTATTHGRSLSPSS PHTVRTAWTSATSGTLGTTHITEPSTGTSHTPAATTGTTQHSTPALSSPHPSSRTTESPP SPGTTTPGHTTATSRTTATATPSKTRTSTLLPSSPTSAPITTVVTTGCEPQCAWSEWLDY SYPMPGPSGGDFDTYSNIRAAGGAVCEQPLGLECRAQAQPGVPLGELGQVVECSLDFGLV CRNREQVGKFKMCFNYEIRVFCCNYGHCPSTPATSSTAMPSSTPGTTWILTELTTTATTT ASTGSTATPSSTPGTAPPPKVLTSPATTPTATSSKATSSSSPRTATTLPVLTSTATKSTA TSVTPIPSSTLGTTGTLPEQTTTPVATMSTIHPSSTPETTHTSTVLTTKATTTRATSSTS TPSSTPGTTWILTELTTAATTTAATGPTATPSSTPGTTWILTELTTTATTTASTGSTATP SSTPGTTWILTEPSTTATVTVPTGSTATASSTQATAGTPHVSTTATTPTVTSSKATPSSS PGTATALPALRSTATTPTATSFTAIPSSSLGTTWTRLSQTTTPTATMSTATPSSTPETVH TSTVLTATATTTGATGSVATPSSTPGTAHTTKVPTTTTTGFTATPSSSPGTALTPPVWIS TTTTPTTTTPTTSGSTVTPSSIPGTTHTARVLTTTTTTVATGSMATPSSSTQTSGTPPSL TTTATTITATGSTTNPSSTPGTTPITPVLTSTATTPAATSSKATSSSSPRTATTLPVLTS TATKSTATSFTPIPSSTLWTTWTVPAQTTTPMSTMSTIHTSSTPETTHTSTVLTTTATMT RATNSTATPSSTLGTTRILTELTTTATTTAATGSTATLSSTPGTTWILTEPSTIATVMVP TGSTATASSTLGTAHTPKVVTTMATMPTATASTVPSSSTVGTTRTPAVLPSSLPTFSVST VSSSVLTTLRPTGFPSSHFSTPCFCRAFGQFFSPGEVIYNKTDRAGCHFYAVCNQHCDID RFQGACPTSPPPVSSAPLSSPSPAPGCDNAIPLRQVNETWTLENCTVARCVGDNRVVLLD PKPVANVTCVNKHLPIKVSDPSQPCDFHYECECICSMWGGSHYSTFDGTSYTFRGNCTYV LMREIHARFGNLSLYLDNHYCTASATAAAARCPRALSIHYKSMDIVLTVTMVHGKEEGLI LFDQIPVSSGFSKNGVLVSVLGTTTMRVDIPALGVSVTFNGQVFQARLPYSLFHNNTEGQ CGTCTNNQRDDCLQRDGTTAASCKDMAKTWLVPDSRKDGCWAPTGTPPTASPAAPVSSTP TPTPCPPQPLCDLMLSQVFAECHNLVPPGPFFNACISDHCRGRLEVPCQSLEAYAELCRA RGVCSDWRGATGGLCDLTCPPTKVYKPCGPIQPATCNSRNQSPQLEGMAEGCFCPEDQIL FNAHMGICVQACPCVGPDGFPKFPGERWVSNCQSCVCDEGSVSVQCKPLPCDAQGQPPPC NRPGFVTVTRPRAENPCCPETVCVCNTTTCPQSLPVCPPGQESICTQEEGDCCPTFRCRP QLCSYNGTFYGVGATFPGALPCHMCTCLSGDTQDPTVQCQEDACNNTTCPQGFEYKRVAG QCCGECVQTACLTPDGQPVQLNETWVNSHVDNCTVYLCEAEGGVHLLTPQPASCPDVSSC RGSLRKTGCCYSCEEDSCQVRINTTILWHQGCETEVNITFCEGSCPGASKYSAEAQAMQH QCTCCQERRVHEETVPLHCPNGSAILHTYTHVDECGCTPFCVPAPMAPPHTRGFPAQEAT AV |
|||||
| Target Bioclass |
Enzyme
|
|||||
| Family |
Peptidase C2 family
|
|||||
| Function |
Calcium-regulated non-lysosomal thiol-protease which catalyzes limited proteolysis of substrates involved in cytoskeletal remodeling and signal transduction. May play a role in insulin-stimulated glucose uptake.
|
|||||
| Uniprot ID | ||||||
| Ensemble ID | ||||||
| HGNC ID | ||||||
Target Site Mutations in Different Cell Lines
Probe(s) Labeling This Target
ABPP Probe
| Probe name | Structure | Binding Site(Ratio) | Interaction ID | Ref | |
|---|---|---|---|---|---|
|
IPM Probe Info |
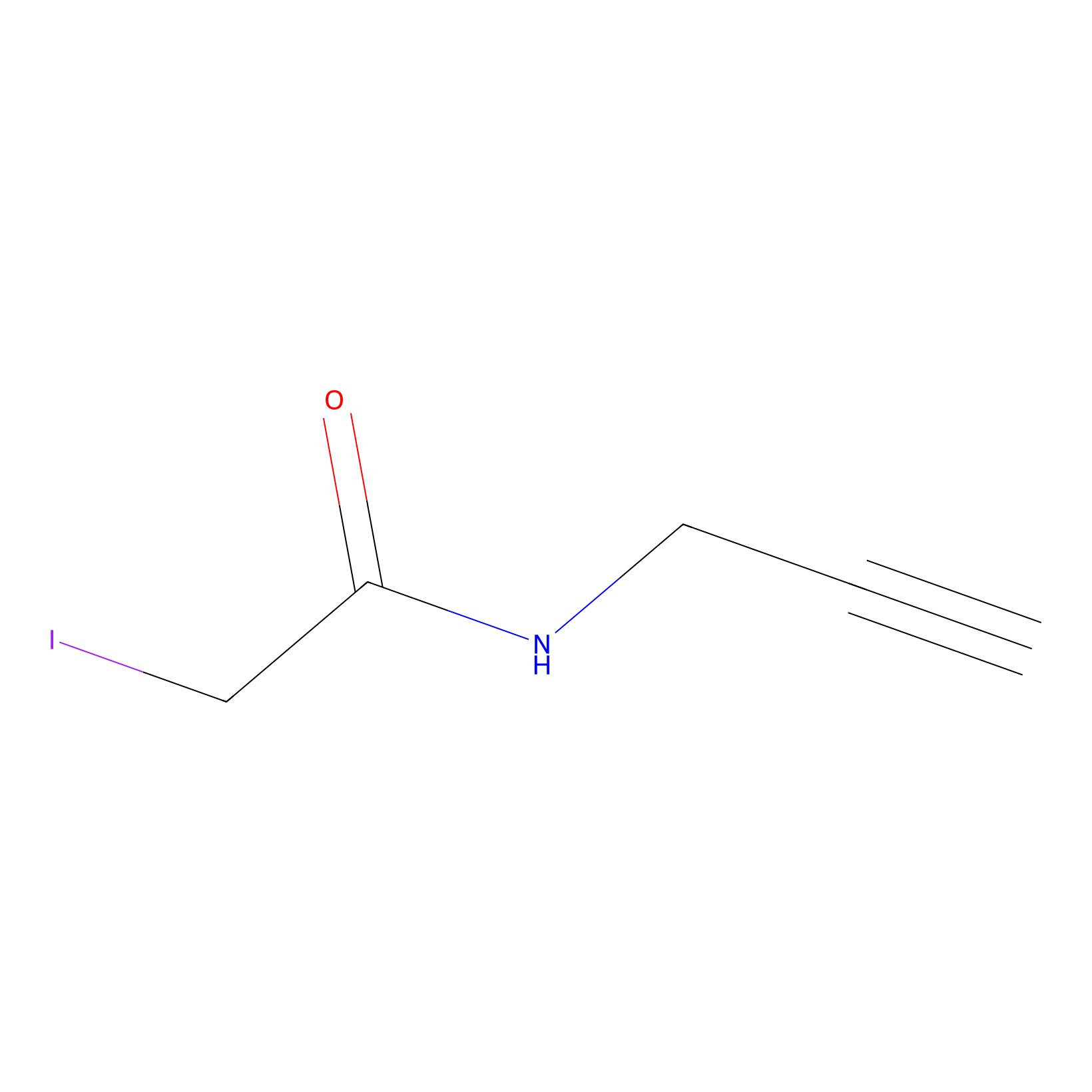 |
C130(1.61) | LDD2229 | [1] | |
|
DBIA Probe Info |
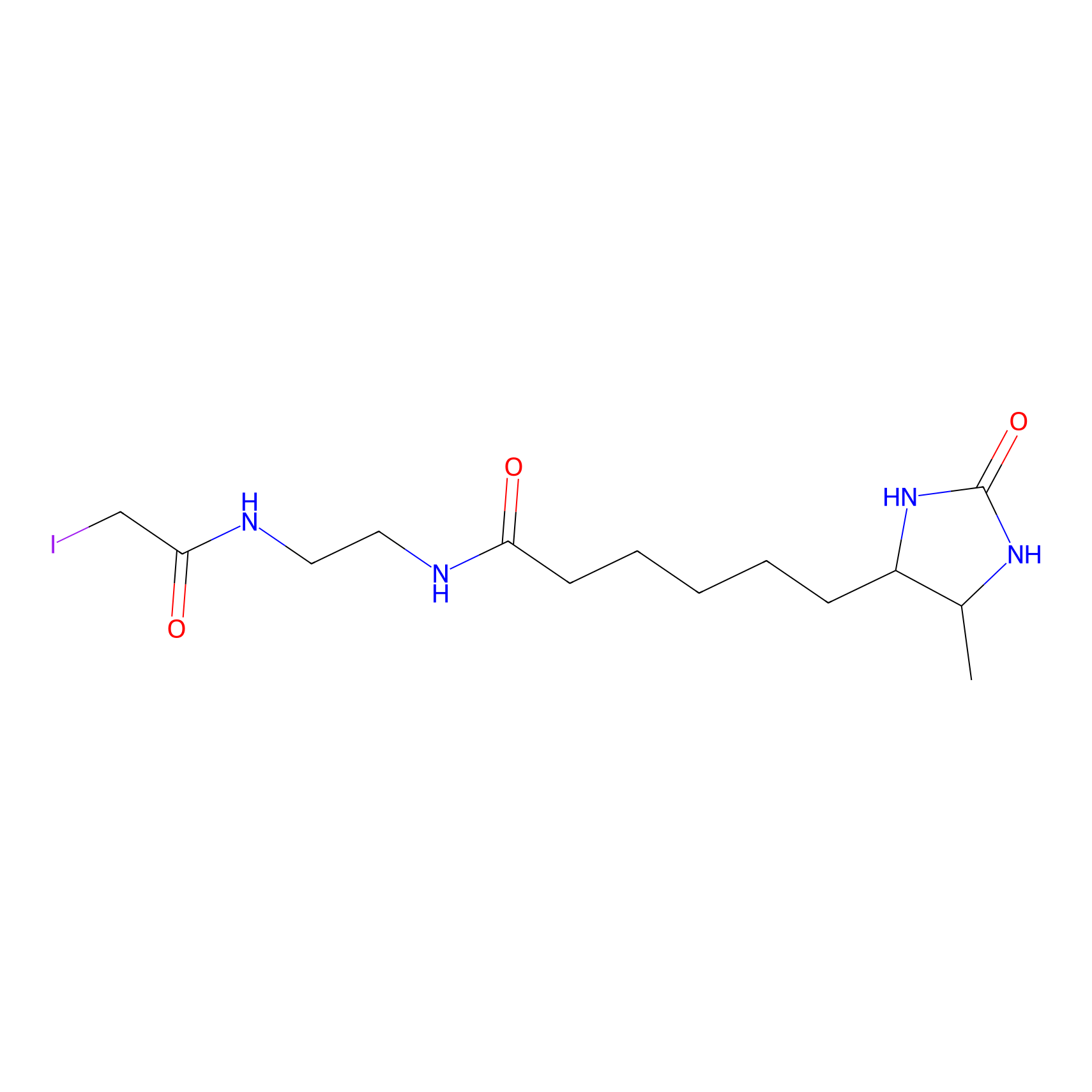 |
C355(0.90) | LDD2470 | [2] | |
|
Crotonaldehyde Probe Info |
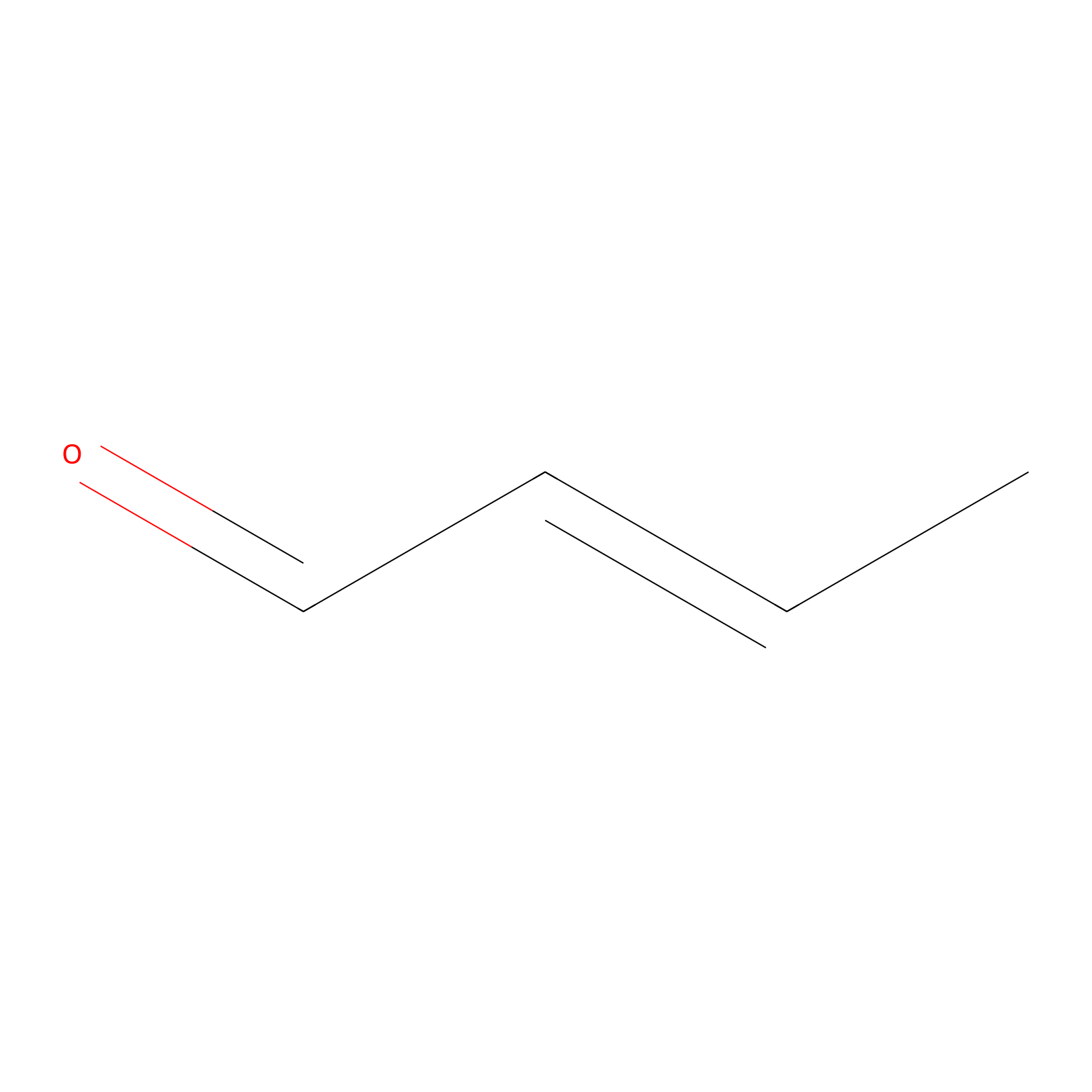 |
N.A. | LDD0219 | [3] | |
|
Methacrolein Probe Info |
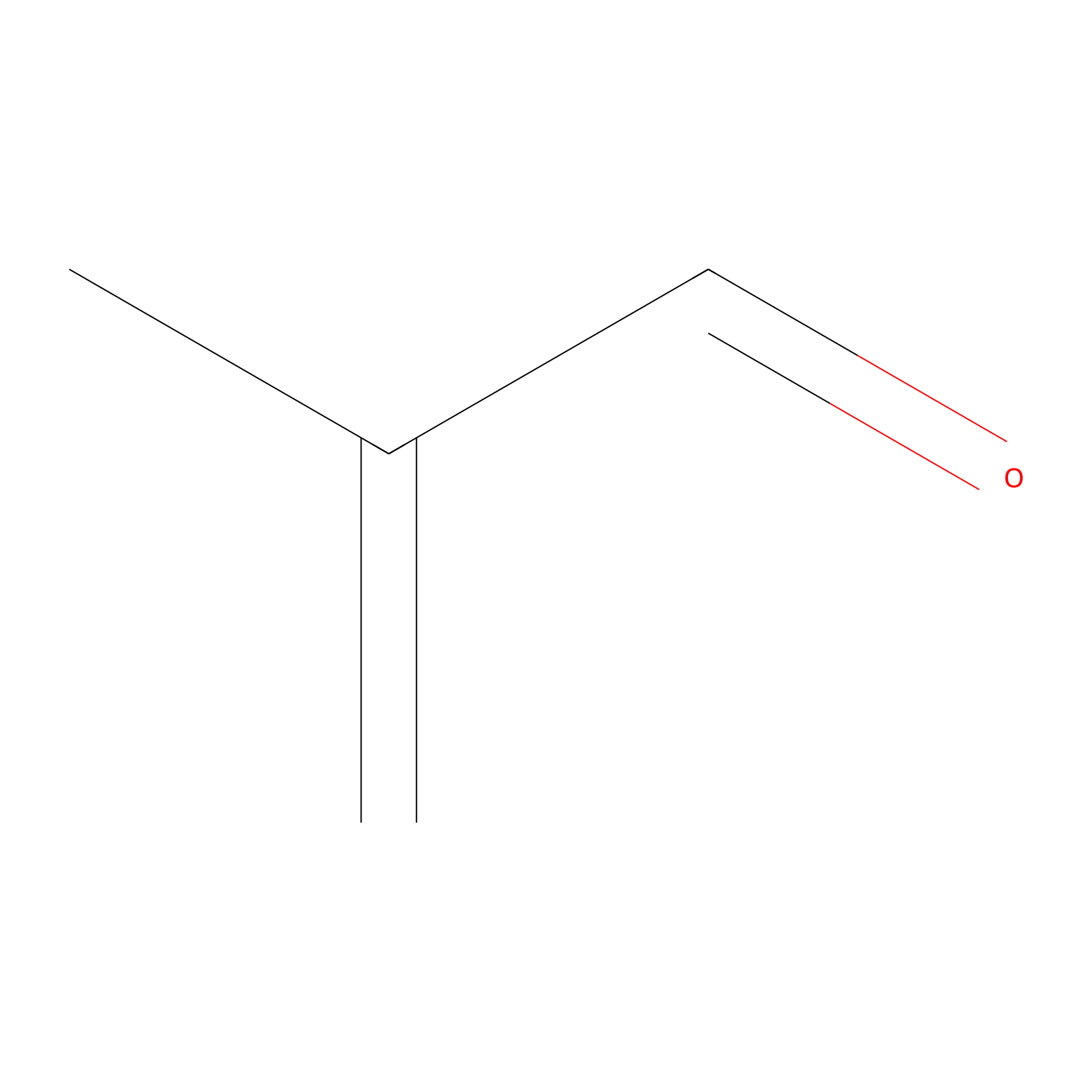 |
N.A. | LDD0218 | [3] | |
Competitor(s) Related to This Target
The Interaction Atlas With This Target
The Protein(s) Related To This Target
Enzyme
| Protein name | Family | Uniprot ID | |||
|---|---|---|---|---|---|
| Frataxin, mitochondrial (FXN) | Frataxin family | Q16595 | |||
Transporter and channel
| Protein name | Family | Uniprot ID | |||
|---|---|---|---|---|---|
| Huntingtin (HTT) | Huntingtin family | P42858 | |||
Other
References