
Details of the Target
General Information of Target
| Target ID | LDTP08051 | |||||
|---|---|---|---|---|---|---|
| Target Name | CUB and sushi domain-containing protein 3 (CSMD3) | |||||
| Gene Name | CSMD3 | |||||
| Gene ID | 114788 | |||||
| Synonyms |
KIAA1894; CUB and sushi domain-containing protein 3; CUB and sushi multiple domains protein 3 |
|||||
| 3D Structure | ||||||
| Sequence |
MKGIRKGESRAKESKPWEPGKRRCAKCGRLDFILMKKMGIKSGFTFWNLVFLLTVSCVKG
FIYTCGGTLKGLNGTIESPGFPYGYPNGANCTWVIIAEERNRIQIVFQSFALEEEYDYLS LYDGHPHPTNFRTRLTGFHLPPPVTSTKSVFSLRLTSDFAVSAHGFKVYYEELQSSSCGN PGVPPKGVLYGTRFDVGDKIRYSCVTGYILDGHPQLTCIANSVNTASWDFPVPICRAEDA CGGTMRGSSGIISSPSFPNEYHNNADCTWTIVAEPGDTISLIFTDFQMEEKYDYLEIEGS EPPTIWLSGMNIPPPIISNKNWLRLHFVTDSNHRYRGFSAPYQGSSTLTHTTSTGELEEH NRTTTGAIAVASTPADVTVSSVTAVTIHRLSEEQRVQVTSLRNSGLDPNTSKDGLSPHPA DTQSTRRRPRHAEQIERTKELAVVTHRVKKAIDFKSRGFKLFPGKDNSNKFSILNEGGIK TASNLCPDPGEPENGKRIGSDFSLGSTVQFSCDEDYVLQGAKSITCQRIAEVFAAWSDHR PVCKVKTCGSNLQGPSGTFTSPNFPFQYDSNAQCVWVITAVNTNKVIQINFEEFDLEIGY DTLTIGDGGEVGDPRTVLQVLTGSFVPDLIVSMSSQMWLHLQTDESVGSVGFKVNYKEIE KESCGDPGTPLYGIREGDGFSNRDVLRFECQFGFELIGEKSIVCQENNQWSANIPICIFP CLSNFTAPMGTVLSPDYPEGYGNNLNCIWTIISDPGSRIHLSFNDFDLESQFDFLAVKDG DSPESPILGTFTGAEVPSHLTSNSHILRLEFQADHSMSGRGFNITYNTFGHNECPDPGIP INARRFGDNFQLGSSISVICEEGFIKTQGTETITCILMDGKVMWSGLIPKCGAPCGGHFS APSGVILSPGWPGYYKDSLNCEWVIEAEPGHSIKITFERFQTELNYDVLEVHDGPNLLSP LLGSYNGTQVPQFLFSSSNFIYLLFTTDNSRSNNGFKIHYESVTVNTYSCLDPGIPVHGR RYGHDFSIGSTVSFSCDSGYRLSHEEPLLCEKNHWWSHPLPTCDALCGGDVRGPSGTILS PGYPEFYPNSLNCTWTVDVTHGKGVQFNFHTFHLEDHHDYLLITENGSFTQPLARLTGSD LPPTINAGLYGNFRAQLRFISDFSISYEGFNITFSEYNLEPCEDPGIPQYGSRIGFNFGI GDTLTFSCSSGYRLEGTSEIICLGGGRRVWSAPLPRCVAECGASATNNEGILLSPNYPLN YENNHECIYSIQVQAGKGINISARTFHLAQGDVLKIYDGKDKTTHLLGAFTGASMRGLTL SSTSNQLWLEFNSDTEGTDEGFQLVYTSFELSHCEDPGIPQFGYKISDQGHFAGSTIIYG CNPGYTLHGSSLLKCMTGERRAWDYPLPSCIAECGGRFKGESSGRILSPGYPFPYDNNLR CMWMIEVDPGNIVSLQFLAFDTEASHDILRVWDGPPENDMLLKEISGSLIPEGIHSTLNI VTIQFDTDFYISKSGFAIQFSSSVATACRDPGVPMNGTRNGDGREPGDTVVFQCDPGYEL QGEERITCIQVENRYFWQPSPPVCIAPCGGNLTGSSGFILSPNFPHPYPHSRDCDWTITV NADYVISLAFISFSIEPNYDFLYIYDGPDSNSPLIGSFQDSKLPERIESSSNTMHLAFRS DGSVSYTGFHLEYKAKLRESCFDPGNIMNGTRLGMDYKLGSTVTYYCDAGYVLQGYSTLT CIMGDDGRPGWNRALPSCHAPCGSRSTGSEGTVLSPNYPKNYSVGHNCVYSIAVPKEFVV FGQFVFFQTSLHDVVEVYDGPTQQSSLLSSLSGSHSGESLPLSSGNQITIRFTSVGPITA KGFHFVYQAVPRTSSTQCSSVPEPRFGRRIGNEFAVGSSVLFDCNPGYILHGSIAIRCET VPNSLAQWNDSLPTCIVPCGGILTKRKGTILSPGYPEPYDNNLNCVWKITVPEGAGIQVQ VVSFATEHNWDSLDFYDGGDNNAPRLGSYSGTTIPHLLNSTSNNLYLNFQSDISVSAAGF HLEYTAIGLDSCPEPQTPSSGIKIGDRYMVGDVVSFQCDQGYSLQGHSHITCMPGPVRRW NYPIPICLAQCGGAMSDFSGVILSPGFPGNYPSSLDCTWTINLPIGFGVHLQFVNFSTET IHDYLEVRSGSSETSTVIGRLSGPQIPSSLFSTTHETSLYFHSDYSQNKQGFHIVYQAYQ LQSCPDPRPFRNGFVIGNDFTVGQTISFECFPGYTLIGNSALTCLHGVSRNWNHPLPRCE ALCGGNITAMNGTIYSPGYPDEYPNFQDCFWLVRVPPGNGIYINFTVLQTEPIYDFITVW DGPDQNSPQIGQFSGNTALESVYSTSNQILIKFHSDFTTSGFFVLSYHAYQLRVCQPPPP VPNAEILTEDDEFEIGDIIRYQCLPGFTLVGNAILTCRLGERLQMDGAPPVCQVLCPANE LRLDSTGVILSPGYPDSYPNLQMCAWSISVEKGYNITMFVEFFQTEKEFDVLQVYDGPNI QSPVLISLSGDYSSAFNITSNGHEVFLQWSADHGNNKKGFRIRYIAFYCSTPESPPHGYI ISQTGGQLNSVVRWACDRGFRLVGKSSAVCRKSSYGYHAWDAPVPACQAISCGIPKAPTN GGILTTDYLVGTRVTYFCNDGYRLSSKELTTAVCQSDGTWSNHNKTPRCVVVTCPSINSF ILEHGRWRIVNGSHYEYKTKVVFSCDPGYHGLGPASIECLPNGTWSWRNERPYCQIISCG ELPTPPNGNKIGTQTSYGSTAIFTCDLGFMLVGSAVRECLSSGLWSESETRCLAGHCGIP ELIVNGQVIGENYGYRDTVVYQCNPGFRLIGSSVRICQQDHNWSGQLPSCVPVSCGHPGS PIYGRTSGNGFNFNDVVTFSCNIGYLMQGPTKAQCQANRQWSHPPPMCKVVNCSDPGIPA NSKRESKIEHGNFTYGTVVFYDCNPGYFLFGSSVLICQPNGQWDKPLPECIMIDCGHPGV PPNAVLSGEKYTFGSTVHYSCTGKRSLLGQSSRTCQLNGHWSGSQPHCSGDATGTCGDPG TPGHGSRQESNFRTKSTVRYACDTGYILHGSEERTCLANGSWTGRQPECKAVQCGNPGTT ANGKVFRIDGTTFSSSVIYSCMEGYILSGPSVRQCTANGTWSGTLPNCTIISCGDPGIPA NGLRYGDDYVVGQNVSYMCQPGYTMELNGSRIRTCTINGTWSGVMPTCRAVTCPTPPQIS NGRLEGTNFDWGFSISYICSPGYELSFPAVLTCVGNGTWSGEVPQCLPKFCGDPGIPAQG KREGKSFIYQSEVSFSCNFPFILVGSSTRICQADGTWSGSSPHCIEPTQTSCENPGVPRH GSQNNTFGFQVGSVVQFHCKKGHLLQGSTTRTCLPDLTWSGIQPECIPHSCKQPETPAHA NVVGMDLPSHGYTLIYTCQPGFFLAGGTEHRVCRSDNTWTGKVPICEAGSKILVKDPRPA LGTPSPKLSVPDDVFAQNYIWKGSYNFKGRKQPMTLTVTSFNASTGRVNATLSNSNMELL LSGVYKSQEARLMLRIYLIKVPAHASVKKMKEENWAMDGFVSAEPDGATYVFQGFIQGKD YGQFGLQRLGLNMSEGSNSSNQPHGTNSSSVAIAILVPFFALIFAGFGFYLYKQRTAPKT QYTGCSVHENNNGQAAFENPMYDTNAKSVEGKAVRFDPNLNTVCTMV |
|||||
| Target Bioclass |
Other
|
|||||
| Family |
CSMD family
|
|||||
| Subcellular location |
Cell membrane
|
|||||
| Function | Involved in dendrite development. | |||||
| Uniprot ID | ||||||
| Ensemble ID | ||||||
| HGNC ID | ||||||
Target Site Mutations in Different Cell Lines
Probe(s) Labeling This Target
ABPP Probe
| Probe name | Structure | Binding Site(Ratio) | Interaction ID | Ref | |
|---|---|---|---|---|---|
|
NAIA_4 Probe Info |
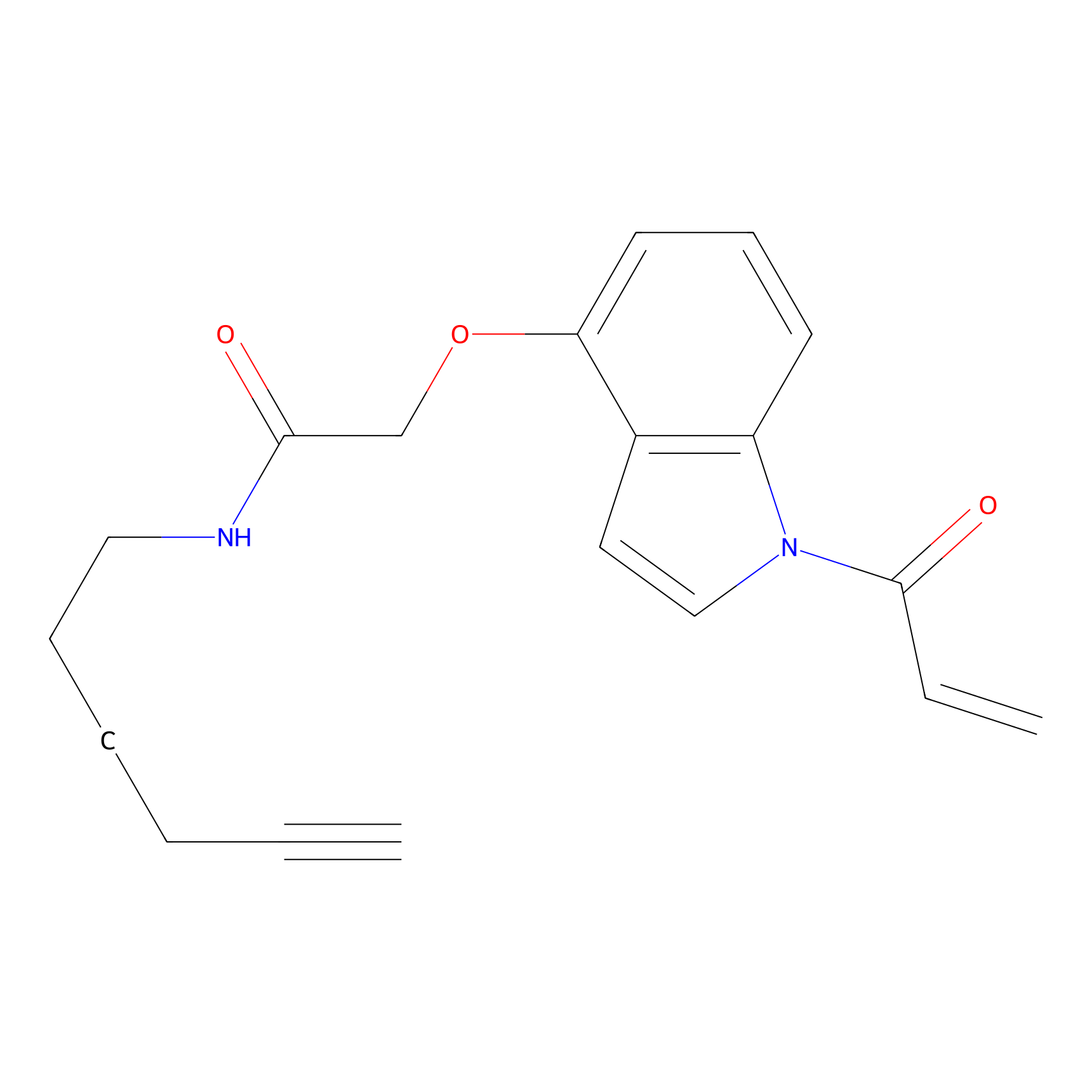 |
C574(0.00); C548(0.00) | LDD2226 | [1] | |